
MongoDB服务器基础篇
MongoDB服务器基础篇
==前言==
注意服务器是一个网站,而客户端通过网站的接口(这里通常27017)连接服务器。
数据结构:数据库(database)——集合(collection)——文档(document)——字段
数据库:网站中的大文件夹。默认有三个:admin、local、config
集合:小文件夹,mysql是表
文档:存取数据的基本单元(Bson格式),mysql是记录。另外还有一种FridFS文件系统可以提供更大的文件系统
字段:则是文档内的数据的分段,每个字段都有无数字典。
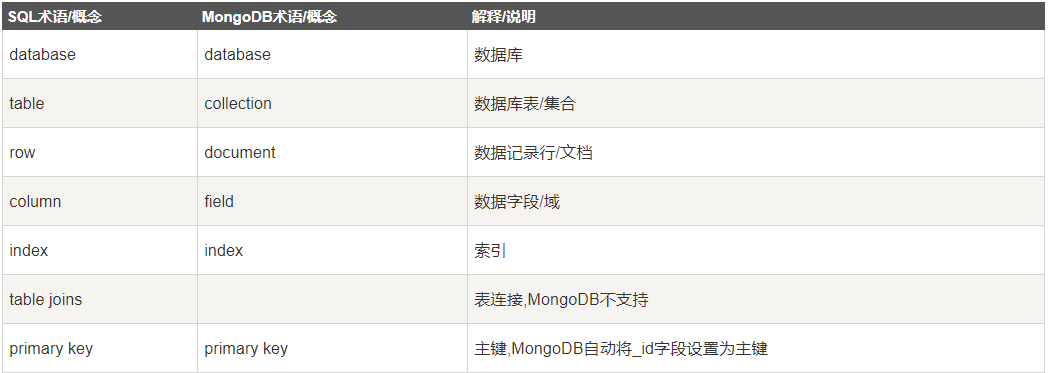
数据类型:
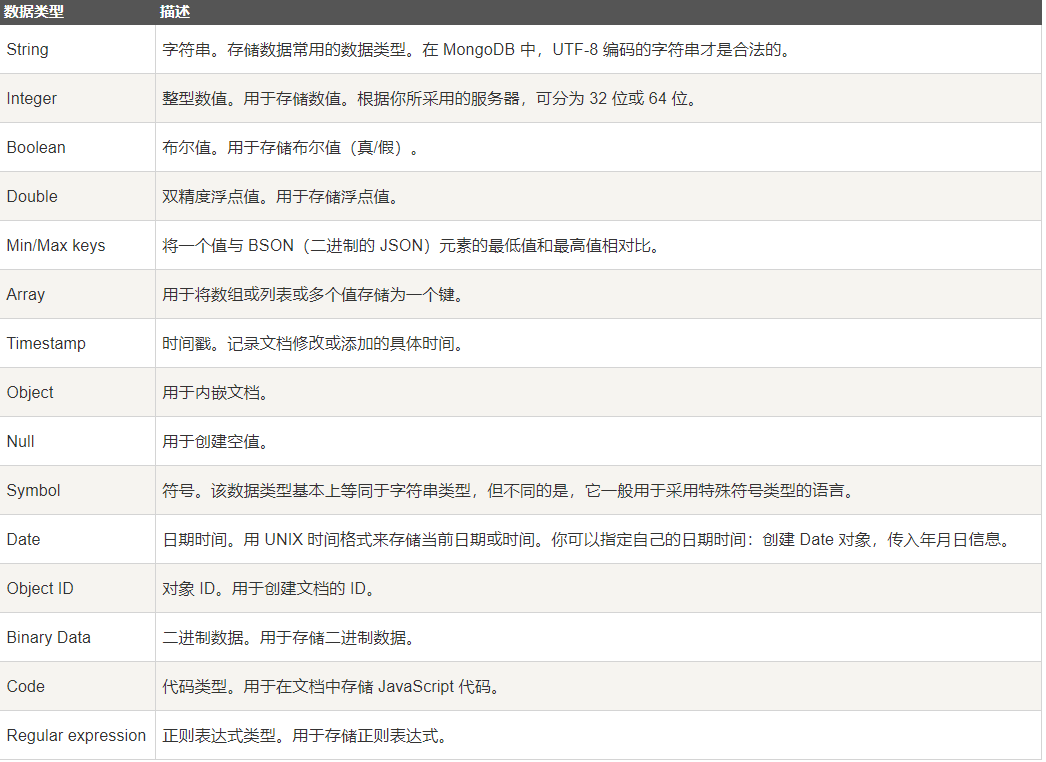
参考文档:https://www.runoob.com/mongodb/mongodb-databases-documents-collections.html
环境:
先下载Mongodb环境,
1. 部署服务器和连接服务器测试
Windows:
1) 启动,部署服务器
先创建一个文件夹放服务器的数据库,这里在bin同级目录下创建data,里面再创建db,以下为两种方法
方法1:命令行启动:
直接在bin目录下用mongod --dbpath=..\data\db(在目录db下创建服务器,并立即启动)
==【注】==
-
mongodb默认数据库的存放位置其实就是\data\db
-
启动信息中可以看到,直接启动mongoDB的默认地址是127.0.0.1(本地服务器),默认端口是27017,如果我们想改变默认的启动端口,可以通过命令行后面–port来指定端口。
-
为了方便我们每次启动,可以将安装目录的bin目录设置到环境变量的path中, bin 目录下是一些常用命令,比如 mongod 启动服务用的, mongo 客户端连接服务用的。
方法2:配置文件启动:
也可用config的配置文件来启动,在bin同级目录下创建config文件夹,再创建mongod.conf文档
输入命令mongod -f ..\config\mongod.conf 或 mongod --config ..\config\mongod.conf
storage:
#The directory where the mongod instance stores its data.Default Value is "\data\db" on Windows
#注意这里通过这个配置文件启动早已创建好的服务器(方法1创建的),这条路径是刚刚创建创建服务器的位置
dbPath:E:\test_code\mongodb-win32-x86_64-2008plus-ssl-4.0.12\data\db
#注意前面是空格,配置文件不可有tab
#路径:若路径中有空格,则需要加双引号;一般填路径无需双引号,如果加上双引号,把盘符\改成/或//;
另外配置文件可再详细(设置了多设置了日志存储文件,并设置改端口IP,可改成服务器的局域网IP)
systemLog:
destination: file
#The path of the log file to which mongod or mongos should send all diagnostic logging information
path: "E:/test/mongodb/mongodb/data/log/mongodb.log"
logAppend: true
storage:
journal:
enabled: true
#The directory where the mongod instance stores its data.Default Value is "/data/db".
dbPath: "E:/test/mongodb/mongodb/data/db"
net:
#bindIp: 127.0.0.1
port: 27017
setParameter:
enableLocalhostAuthBypass: false
==【注】配置文件不可有tab制表符,只可用空格,空格不可过多,==
2) 客户端连接服务器:
这里是测试刚才创建的服务器,不可把服务器的CMD窗口关闭
服务器里一般默认有三个数据库)
方法1.命令行monogo(适合本地连接)
#无任何参数,一般访问本地
mongo
#或带参数,指定本地地址及端口
mongo --host=127.0.0.1 --port=27017
其他一些命令行操作(MongoDB javascript shell是一个基于javascript的解释器,故是支持js程序的。)
show dbs //显示数据库,也可写databases
exit //离开mongodb
mongo --help //更多参数
方法2:利用图形化界面mongodb Compass连接服务器
直接打开输入地址和端口即可,若本地服务器直接填localhost或者127.0.0.1
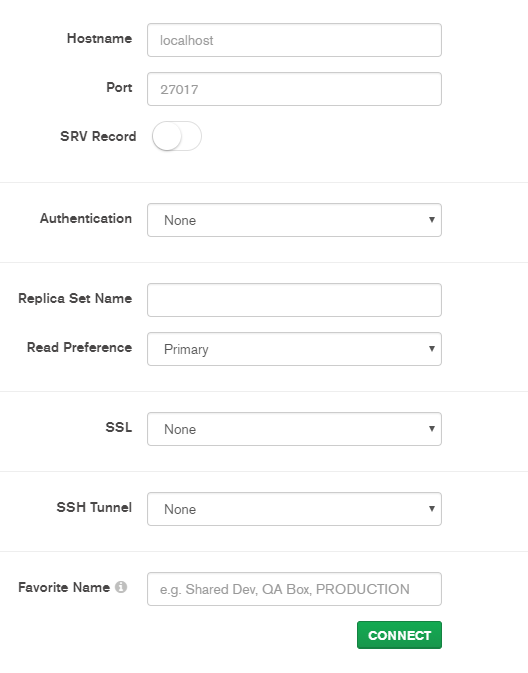
Linux:
这里介绍真正用虚拟机或服务器搭建非本地的服务器
1.预操作
(1) 官网下载mongodb的linux压缩包 mongod-linux-x86_64-4.0.10.tgz 。 压缩包可直接使用,免安装,省心
(2)上传压缩包到Linux中,解压到当前目录: tar -xvf mongodb-linux-x86_64-4.0.10.tgz
(3)为了方便管理mongodb文件,移动解压后的文件夹到指定的目录中: mv mongodb-linux-x86_64-4.0.10 /usr/local/mongodb
(4)==新建几个目录,分别用来存储数据和日志==:
mkdir -p /mongodb/single/data/db #数据存储目录
mkdir -p /mongodb/single/log vi /mongodb/single/mongod.conf #日志存储目录
(5)新建并修改配置文件 配置文件的内容如下:
#设置MongoDB发送所有日志输出的目标指定为文件
systemLog:
#指定对日志的操作是文件操作,默认是命令行操作。这是方便代码维护
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: "/mongodb/single/log/mongod.log"
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。
logAppend: true
storage:
#mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。默认数据存放位置是"/data/db"
dbPath: "/mongodb/single/data/db"
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
processManagement:
#启用在后台运行mongos或mongod进程的守护进程模式,即保证后台一直运行。
fork: true
net:
#服务实例绑定的IP,默认是localhost,这里是设置服务器局域网的IP
bindIp: localhost,192.168.0.2
#bindIp
#绑定的端口,默认是27017
port: 27017
(6)启动MongoDB服务:/usr/local/mongodb/bin/mongod -f /mongodb/single/mongod.conf
[root@bobohost single]# /usr/local/mongodb/bin/mongod -f /mongodb/single/mongod.conf #启动进程
about to fork child process, waiting until server is ready for connections.
forked process: 90384
child process started successfully, parent exiting
注意:
若无 successfully 提示则表示失败。一般是配置文件有问题。
可以通过通过进程来查看服务是否启动了:ps -ef |grep mongod
[root@bobohost single]# ps -ef |grep mongod #查询进程
root 90384 1 0 8月26 ? 00:02:13 /usr/local/mongdb/bin/mongod -f /mongodb/single/mongod.conf
(7)分别使用mongo命令和compass工具来连接测试。 ==提示==:如果远程连接不上,需要配置防火墙放行,或直接关闭linux防火墙
#查看防火墙状态
systemctl status firewalld
#临时关闭防火墙
systemctl stop firewalld
#开机禁止启动防火墙
systemctl disable firewalld
(8)停止关闭服务(linux关闭服务器比较麻烦) 停止服务的方式有两种:快速关闭和标准关闭,下面依次说明: (一)快速关闭方法(快速,简单,数据可能会出错) 目标:通过系统的kill命令直接杀死进程: 杀完要检查一下,避免有的没有杀掉。 ==【补充】== 如果一旦是因为数据损坏,则需要进行如下操作: 1)删除lock文件: 2)修复数据:
(二)标准的关闭方法(数据不容易出错,但麻烦): 目标:通过mongo客户端中的shutdownServer命令来关闭服务 主要的操作步骤参考如下: 3 基本常用命令 #bindIp #绑定的端口,默认是27017 port: 27017
2.启动:一般用配置文件配置(详细)
-
首先创建数据存储目录和日志存储目录(均是数据库,即文件)
-
创建配置文件,指定上面两个目录,并自动后台执行,确定服务器地址和端口(一般是云服务器所在的局域网地址,非公网)
3.连接:同上,注意连公网(不同于配置服务器地址)
2 数据库数据处理
可以理解为文件夹是数据库;
数据库内有文件(数据库表);
每个文档内有多条数据,一条数据即数据记录行,也就是是超多的键:值
其中有主键_id
对比关系数据库RDBMS

一般内置三个服务器:
Admin:类似root库,存储用户信息及相应权限
Local:集群算数处理时保证绝对不会复制
Config:用于创建集群的分片
2.1 数据库
基础操作
创建/切换数据库(文件夹):
格式:use 数据库名
【注】只有数据库有内容时(集合),才存储到硬盘,否则只是在内存中
查询当前数据库:
格式:db
删除数据库:
格式:db.dropdatabase()
类似js的语法,保证当前使用的是想要删除的数据库,在输入命令
数据库管理
数据库的备份和恢复
要注意这里的命令是在系统命令行输入的,其他操作都是在mongodb服务器的操作
恢复的数据是以前删除的json和bson的数据
//数据备份
mongodump -h dbhost -d dbname -o dbdirectory
//-h:MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017。默认是本地端,即127.0.0.1
//-d:需要备份的数据库名,例如:test
//-o:备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。
//数据恢复
mongorestore -h <hostname><:port> -d 数据库名 <path>
//--host <:port> 或 -h <:port> : MongoDB所在服务器地址,默认为: localhost:27017
//--db,-d :需要恢复的数据库名,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
//--drop :恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
//<path> :mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:\data\dump\test。
//--dir :指定备份的目录
//不可同时指定 <path> 和 --dir 选项
数据库的复制
为了防止数据库的死机导致数据完全丢失,所以会创建很多副本集,一个死了用其他副本集
整体结构是有一个数据库做主节点,其余是从节点。主节点负责直接和客户端收发数据,并产生操作的日志oplog,从节点读取主节点的oplog然后做同样的操作,从而保证数据库的自动备份
数据库的分片
对于超大型的服务器,要处理海量的数据,一台机器可能不足以存储数据,并且吞吐量也不满足要求,所以会将数据分割给多台机器
分片的启动的客户端称shard serve
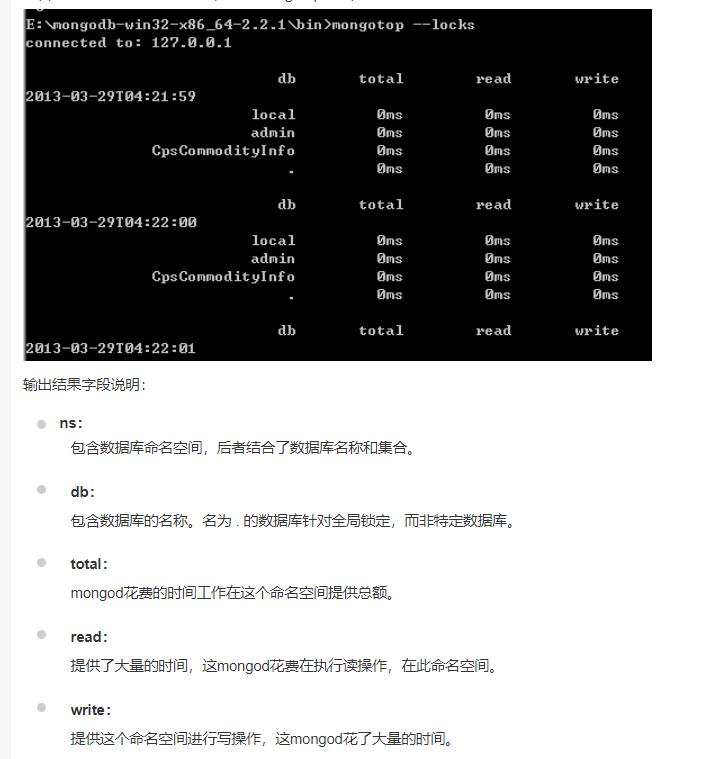
数据库的监控
mongostat和mongotop是和mongod和mongo一样在bin目录下,只需到该目录启动即可
-
mongostat实时监控mongodb的运行状况,一般在数据库变慢时使用
-
mongotop可以跟踪mongodb数据库的情况。检测在不同数据上花费的时间
格式:
mongotop <sleeptime>,sleeptime是等待的时间
2.2 集合
-
集合实际是文档,文档中有一条条数据每条数据可以有个键和值,基本操作是==增删改减==。
#以下为一个集合,一个数据一个{},其中有多个内容 {"_id":"1","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08- 05T22:08:15.522Z"),"likenum":NumberInt(1000)}, {"_id":"2","userid":"1005","nickname":"伊人憔悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888)}, {"_id":"3","userid":"1004","nickname":"杰克船长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"}, -
文档格式是bson,其实是类似于json的数据格式。{数据名:数据;}即=={键:值}==
==一般数字是double类型,其他一般是字符类型==
-
对于每一条数据通常都有自己的主键:==_id==,这是默认的,属性是objectID,内容包括时间戳,机器ID,mongdb服务进程id,最后三个字节为简单的增量值。
也可自定义_id
-
内置方法
NumberInt(数字) double准换为整型数 new_Data() #当前日期 #检查数据问题,一般插入数据有问题mongodb不会反馈,若有问题打印相应问题 try { db.集合名.inserMany([{},{}]); } catch(e){print(e);}
集合操作
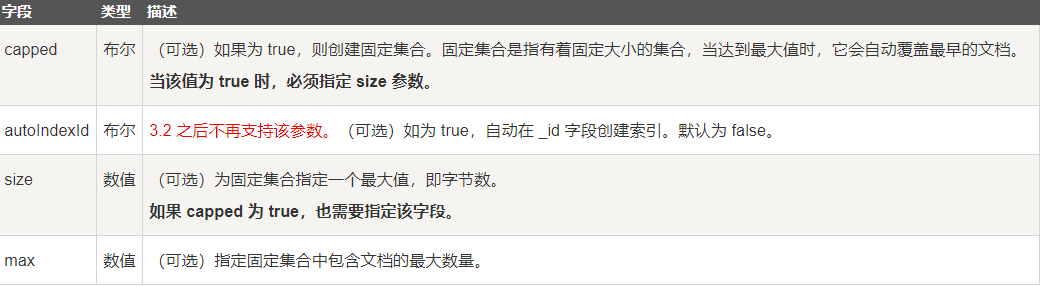
//创建集合
db.createCollection(“集合名“,^参数操作^)
//参数可加可不加
//显示当前库的集合
show collections或show tables
//删除集合:返回true或false
db.集合名.drop()
【注】
- 集合名不可有$或system开头的名称(系统内置集合)
- ==当插入数据时,指定的集合不存在,会自动创建新的集合。所以其实集合操作用的少==
集合中插入数据:
//普通插入
db.集合名.insert({键:值,order:true/false})
//这里键一般是字符,值可以是字符或数字。
//order,true则集合有序,false无序。默认是有序
//插入一条数据
db.集合名.insertOne({键:值,...},^{writeConcern:参数}^)
//writeConcern写入策略,默认1:要求写操作;0是不要求
//插入多条数据
db.集合名.insertMary({数据名:内容…},{数据名:内容}...
^{writeConcern:参数,ordered:参数}^)
//writeConcern写入策略,默认1:要求写操作;0是不要求
//order指定是否顺序写入,默认true是
【注】若插入的数据中_id的值与数据库内部重复,将报错;_
另外有一种save()是可以相同的_id,此时会更新
查询集合
//查询集合所有数据
db.集合名.find(^{条件query}^,^{条件2projection}^)
//无参数即查询所有数据
//query:查询符合条件的数据
//projection:当条件有两个参数时,即投影查询,查找符合条件的数据,并只显示查找的数据信息,一般来说这样的数据只有_id不同
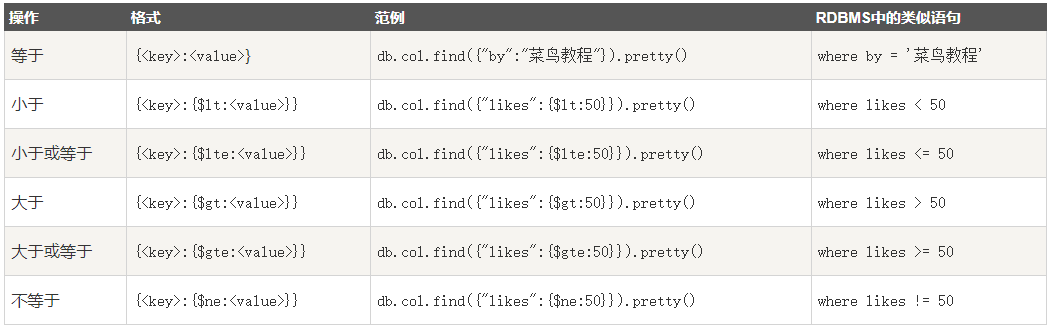
//条件:数字一般用:表等于,其他正则表达有大于等于等
字符串表等于:/字符串/。而其他用$符表示的是正则表达式。
数组用find(键:{$in["内容","内容"...]})
//正则
db.集合名.find({键:{$gt:值1,值2}})
//查询第一个符合条件的数据
db.集合名.findOne(^参数query^,^参数projection^)
//多个条件的查询。AND和OR,以普通查询为例
//AND,逗号即相当于AND,查找同时符合两个条件的数据
db.集合名.find( { $and:[{条件1},{条件2}] } ) 或 db.集合名.find({条件1,条件2})
//OR,$or,查询符合两个条件中任意一个的数据
db.集合名.find( {$or: [{键1:值1,键2:值2},{键3:值3,键4:值4}] } )
//方法
.pretty() //将数据更好看的格式显示
.limit(数字n) //只对前n条数据条件查询,后面不查
.skip(数字n) //跳过前n条数据开始条件查询
以上两个也可拼接.skip(n).limit(m):跳过前n个只查m个
.sort(键:参数) //以某个键的值按顺序排序
//参数:1是升序,-1是降序
.explain(参数) //用来测试查询的性能,一般是测试索引的效果。称为执行计划
//返回值有各种PLAN,重要的事winnerPlan,其中有stage返回一个扫描的操作,COLLSCAN代表集合扫描,即全局扫描。若是fetch则是利用索引抓取
正则代码:
type操作符
假设一个不同数据中含有相同的键,但不用数据键的内容格式不同。假设有一个键叫key,可能第一条数据value是字符串,另一条是数据。可以只取某种数据类型的数据
例:db.col.find({"title":{$type:2}})或db.col.find({"title":{$type:'string'}})
修改集合
格式:
//先查找符合条件的数据,后修改此数据的相应内容
db.集合名.update({条件},{^$操作符:^{修改内容}},^upsert:参数^,^multi:参数^,^writeConcern:参数^)
//修改内容可以加上各种更新操作符。$set,$inc
//$set表示只修改数据中的某条数据,若无此语句,则是把该数据的所有内容擦除,再插入给定的内容
//$inc是自增
//upset:当源数据库无符合要求的数据是否插入:默认false,不插入,true为可插入
//multi:查询数量。默认false,只更新一条默认。true符合条件均修改。注意multi与$同时存在才有效
//writeConcern:抛出异常级别
db.集合名.update({条件},{新的内容}) 把符合条件数据第一条的内容完全擦除再写入新的
db.集合名.update({条件},{$set:{数据名:内容}} 查找符合条件的第一个数据并修改
db.集合名.update({条件},{$set:{数据名:内容},multi:true} 符合条件的所有数据均修改
//实例,只添加第一条:
db.col.update( { "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false );
删除集合
删除方式:justOne:true和false。默认false,删除多条,改true只删一条
db.集合名.remove
(
{query条件},
{
justOne: <boolean>,
writeConcern: <document>
}
)
//query:删除的文档的条件,若不写则是删除所有数据
//justOne:(可选):删除文档的数量,默认false,删除所有符合条件的数据。 true ,则只删除一个文档
//writeConcern:(可选)抛出异常的级别
//新版
db.集合名.deleteOne({条件})//删除一个
db.集合名.deleteMany({条件})//删除多个
//要注意以上删除不释放磁盘空间
db.repairDatabase()
db.集合名.reout(““条件””:)
==查重==
查重其实是非常重要的操作,不光是用户输入的相同信息的过滤,包括可以防止爬虫时重复爬取网站等情况
//查找数据中的某个键所有值的种类(以数组的方式呈现)
db.集合名.distinct({键},^{筛选条件}^)
这里介绍一些去重的算法(针对爬虫):
利用数据库建立索引进行,针对爬取的信息用网站分类或用数据本身进行分类
-
根据url地址进行去重
-
使用场景:
- url地址对应的数据不会变的情况,url地址能够唯一判别一个条数据的情况(一般url地址的数据不变的)
- 思路
- 所有url数据存在redis中
- 拿到url地址,判断url在redis的url的集合中是够存在
- 存在:说明url已经被请求过,不再请求
- 不存在:url地址没有被请求过,则请求把该url存入redis的集合中
- 布隆过滤器(一种将多条数据编码的方式方便快速大量查找,例8条数据编码为三位,满足111才便是某条数据存在)
-
使用多个加密算法加密url地址,得到多个值
-
往对应值的位置把结果设置为1
-
新来一个url地址,一样通过加密算法生成多个值
-
如果对应位置的值全为1,说明这个url地址已经抓过
-
否则没有抓过,就把对应位置的值设置为1
-
-
-
根据数据本身进行去重(一般数据内可能存在评论增加等数据增加的情况)
- 选择特定的字段,使用加密算法(md5,sha1)将字段进行加密,生成字符串,存入redis的集合中
- 后续新来一条数据,同样的方法进行加密,如果得到的字符串在redis中存在,说明数据存在,对数据进行更新,否则说明数据不存在,直接插入
索引
索引是为了方便数据查询的速度,可以把数据按照一种排列规则添加对应的索引,存放在索引表中
默认有一个索引,就是_id
索引的名称一般是键_排序参数。符合索引名称则是键_排序参数_键_排序参数
//查看索引
db.集合名.getIndexes()
//其中会有v:指Mongodb版本。key:即索引的内容。name:即索引的名称。
//查看索引大小
db.col.totalIndexSize()
//删除索引所有
db.col.dropIndexes()
//删除指定索引,可以是索引名称,也可以是以前输入的索引的内容
db.col.dropIndex("索引名称")
//创建索引
db.collection.createIndex({键:排序参数}, ^{参数:参数}^)
//与find().sort()类似,创建一个以某个键为指标的升序或降序的索引。且这个索引可以多个,但第一条为首要
//排序参数1为升序,-1为降序
//参数见如下,设定索引的类型

文档查询
//统计查询,即查询相应记录的数量
db.集合名.count({条件},参数)
//不带参数则是统计所有
聚合
聚合是一种利用管道的方式处理数据并返回结果,一般并不对数据进行改动,只是一定的统计计算。==实际属于查询==
aggergate内的参数是一些筛选条件,管道实际上是指把 前一段筛选出的数据提供给下一条筛选,以达到层层筛选的效果
//基本处理是将每一个{}的处理结果传给下一个{}
db.集合名.aggergate({管道筛选条件1},{管道筛选条件2}...)
//这里管道筛选条件是group、match等操作,内部可以嵌套一些表达式
//其实处理上来说聚合类似于find,但可以做的操作更多,而且是以管道的方式,所以更有优势
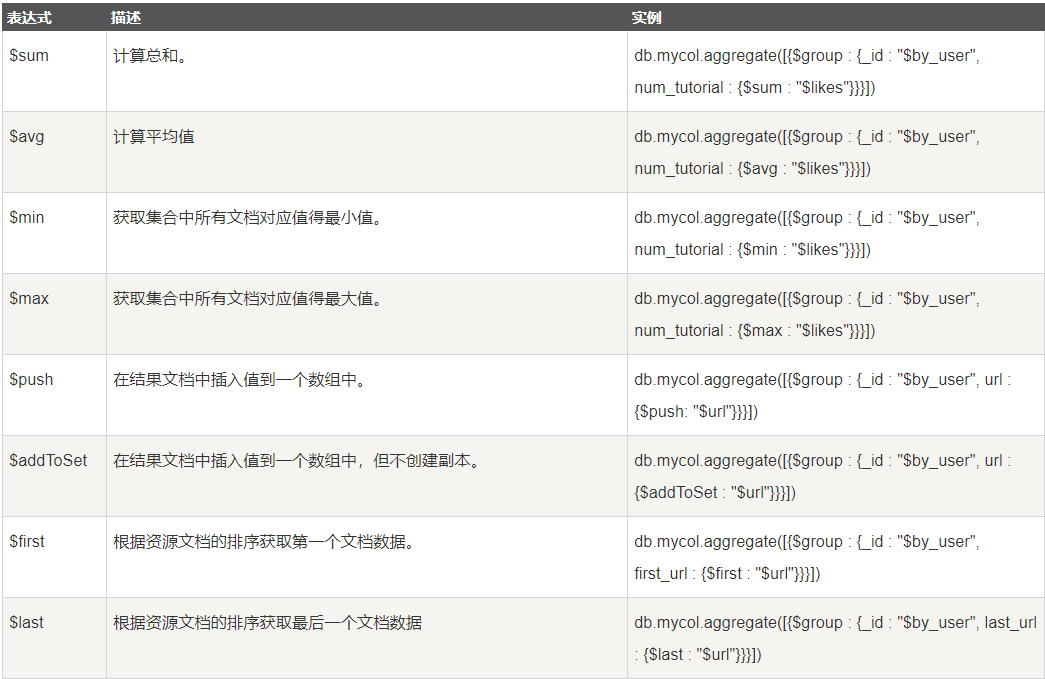
//下表有表达式的图和操作,注意表达式处理的对象一般是key需要$key所有这类key均做此操作
//特别提一下$sum
db.集合名.aggregate([{键:{$sum:1}}])
db.集合名.aggregate([{键:{$sum:$值}}])
//第一个是将统计指定键的数量,有一个这个键就+1
//第一个是将指定键中的值求和
- 表达式
- 管道操作:一般格式:
管道操作符:{操作1,操作2}。内部的操作1,2均是管道处理方式而不是逻辑与的同时处理
$group:将集合中的文档分组,可用于统计结果。
$match: 用于过滤数据,只输出符合条件的文档。相当于MongoDB的标准查询操作。
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$unwind:将文档中的某一个数组类型字段拆分成多条,每包含数组中的一一个值。
$sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置 的有序文档。
$group分组
//$group将文档的分组,用于统计数据。
//$group分组的依据是_id,这是系统内置和group一起工作的,后面的数据则是管道操作
db.集合名.aggregate({ $group: { _id: 键1, 键10:{$sum:1} } });
//这里用了group和sum一起处理数据,表示先将文档以键的值种类分组,再将统计每个组拥有键1的个数
//多条件的group
//假设键中有两种值,分组后的组1有5个拥有键10的数据,组2有6个。处理的结果是{_id:值1,键10:5},{_id:值2,键10=6}
db.集合名.aggregate({ $group: { _id: {键1:"$键1",键1:"$键2"}, 键10:{$sum:1} } });
//_id后面的不仅可以是键值,也可以是一个字典,也就是复合分组。分组的依据有多个。一般用来去重(重复的可以进行sum:1统计处理)。
==【注】==
- 取不同字段的值需要用’’$’‘,例取数据已有的的键
- 分组可以按多个键进行分组,嵌套的形式
{$group:{_id:{键1:"$键1",键2:"$键2"} }}- 结果是:
{_id:{键1:"内容1",键2:"内容11"}},{_id:{键1:"内容2",键2:"内容11"}}类推
- 结果是:
- 以上输出的结果是id底下是一个字典,想要取id下一个字典的键值可以用.取。如:
$_id.键1 - ==group分组的_id也可填null,这样就可以保证不动不做管道处理,只做表达式操作==
$match匹配过滤
db.集合名.aggregate({$match:{键:{^正则操作符:^值}}});
即类似find的普通条件查询
$project重命名数据结构
//由于分组的结果一般是_id表示数据,不好看,可以用project重命名组的名字
db.集合名.aggergate([$project:{新键名:"$旧键名1",旧键名2:1,旧键名3:0}])
//对旧键1的操作实际是重命名为新的键名;旧键2的操作是输出结果有键2,注意前提是前面的管道处理的结果有键2;旧键3的操作是不显示旧键3的输出
project一般放在最后,重命名
$unwind拆分某数组
将文档中的所有的数组类型拆分成多个数据段
$unwind
将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
语法:db.集合名称.aggregate({$unwind:'$字段名称})
//例:
db.集合名.insert({_id:1,item:'t-shirt,size:['S",'M',L')db.t2.aggregate({$unwind: '$size'})
//结果如下:
{ "_id" : 1, "item" : "t-shirt", "size" : "s"}
{ "_id" : 1, "item" : "t-shirt", "size": "M"}
{ "_id" : 1, "item" : "t-shirt", "size": "L"}
//可选参数:preserveNullAndEmptyArrays。
//默认是false,当有的字段有数组,有的没有,系统会忽视那些没有数据的字段当值为true表示保留属性值为空的文档
db. inventory.aggregate( {
$unwind : {
path: '$字段名称',
preserveNullAndEmptyArrays :<boolean> #true或false
}
})
$sort输出排序
db.集合名.aggergate({$sort:{键:1,键2:-1})
//设定以某键升序和降序,和.sort()操作基本一致
$limit限制返回文档数和$skip跳过指定数量的文档
和find的两个方法基本一致
聚合实例
/*需求:
统计出每个country和每个province下的userid的数量(同一个userid只统计一次)
处理对象:
{ "country" : "china", "province" : "sh", "userid" : "a"}
{ "country" : "china", "province" : "sh", "userid" : "b"}
{ "country" : "china", "province" : "sh", "userid" : "a"}
{ "country" : "china", "province" : "sh", "userid" : "c"}
{ "country" : "china", "province" : "bj", "userid" : "da"}
{ "country" : "china", "province" : "bj", "userid" : "fa"}
*/
/*分析
*1.可以看到第三组数据和第一组数据一致,不可同时算入处理对象——>应先去重,不可distinct,可以用把三个键重新分组达到去重效果
*2.要求是对country和province同时分组——>应复合分组
*3.将数据的userid数据数量统计
*4.结果肯定会有_id:{字典}的形式,需要美观——>应取出中的字典单独显示,所以采用$_id.键 的形式
*/
//代码
db.集合名.aggregate(
{$group: {_id: {country:"$country",province:"$province",userid:"$userid"} } },
{$group:{ _id: {country:"$_id.country",province:"$_id.province"}, count:{$sum:1} } },
{$project:{ country:"$_id.country",province:"$_id.province",count:1, _id:0 } }
)
//第一行去重
//第二行统计数据
//第三行将_id底下的字典内容取出,再将_id不显示
Share on
X Facebook LinkedIn BlueskyComments are configured with provider: staticman, but are disabled in non-production environments.
